<<Biblioteca Digital del Portal<<INTERAMER<<Serie Educativa<<Digital Libraries and Virtual Workplaces Important Initiatives for Latin America in the Information Age<<Chapter 4
Colección: INTERAMER
Número: 71
Año: 2002
Autor: Johann Van Reenen, Editor
Título: Digital Libraries and Virtual Workplaces. Important Initiatives for Latin America in the Information Age
Components
To build digital libraries we must ensure that each of the “S” constructs is addressed, and so can use 5S as a checklist or guideline. In operational terms, however, many digital libraries are built out of components that are integrated into a production quality system. Figure 2 highlights some of the most important such components.
In the following subsections we explore issues and sub-components related
to this figure.

Figure 2. Components of a Digital Library
Digital objects
The actual content of digital libraries is made up of a number of digital objects. In some cases these may be thought of as data sets (e.g., a table of results, the genomic information for an individual). In others they may be multimedia information, such as an image, graphic, animation, sound, musical performance, or video. Many can be thought of as documents, which carry content in some structure or structures, perhaps made up of logical or physical divisions such as sections or pages. Some of the objects will be “born digital”, such as this paper, while others may be representations of some physical object (such as a painting that is shown through a digital image) that result from some type of digitization process. Thus, into the foreseeable future, digital libraries will be hybrid constructs, where paper, microforms, and other media carry much of the content that is of interest and only the metadata is in digital form.
Metadata
Digital objects are described, structured, summarized, managed, and otherwise manipulated in surrogate form through the use of “metadata”, which literally means data about data. Three types of metadata are often distinguished: descriptive, structural, and administrative. Metadata is usually produced through a process called “cataloging” that is often carried out by trained librarians. Collections of such information are commonly stored in “catalogs”. In computerized environments, metadata may be automatically or semi-automatically extracted or derived from the original content, or the “full-text” may simply be indexed and searched without involving metadata (as happens on the WWW when search engines are employed). Nevertheless, if metadata is available and can be used along with content terms derived from full-text documents, the result is better than if only one source of evidence is employed (Fox 1983). Yet, if only metadata is available in computer form to describe a digital object, it must be used in digital libraries. Hence, metadata should be used whenever available in a digital library, and is an important aspect in many such systems.
Repositories and Harvesting
As can be seen in Figure 3, we can think of digital libraries as containing a collection of digital objects (DOs), each of which has one or more sets of metadata objects (MDOs) associated. This “repository” part of a digital library may, as is the case in the Open Archives Initiative (Van de Sompel 2000), follow certain conventions (Van de Sompel & Lagoze, 2000). In particular, according to the latest specifications, an “Open Archive” (OA) is a computer system with a WWW server that behaves according to an OA protocol to allow other computers to harvest metadata from it. That protocol supports requests to, for example:
- list what types of metadata format are present,
- list what structure of sets and subsets are used to organize or partition the content,
- disseminate or return a particular MDO, or
- list URIs (unique identifiers) for all MDOs added during a particular date range.

Figure 3. Open Archives Repository
In particular, every OA must be able to
return MDOs that conform to the Dublin Core and are coded in XML. They must
have documented policies about what DOs are included, what “archiving” is
in place, and what terms and conditions apply to use, if any. Having a repository
component that is an OA means that access to digital library content is open,
ensuring widespread interoperability at one important level.
At a slightly deeper level, interoperability among digital libraries requires that digital objects be accessible through some scheme for universal identifier names (e.g., URNs). MDOs thus have an URN that facilitates access (if authorized) to the corresponding DO. A likely policy for an OA is to use some specific type of URN (e.g., OCLC’s PURL or CNRI’s handle – also employed for Digital Object Identifiers, DOIs). In today’s ubiquitous WWW environment, it is presumed that users and computers will be able to retrieve a desired DO if its identifier is known.
Rights Management
Considering again Figure 2, we note that in the layer above data, multimedia information, and repositories are the “rights manager” which must protect intellectual property rights. In the trivial case, which fortunately is common, content is freely available so nothing is needed here. In some cases too, where content is encrypted, content management is outside the scope of the digital library, since secure objects are stored and retrieved and the steps of encryption and decryption occur remotely. Similarly, some content may have “watermarks” added in a way that makes removal difficult, so that subsequent access outside the digital library can be monitored or controlled.
However, as e-commerce, e-government, and other movements spread, it will be crucial for many digital libraries to manage rights. This typically involves a number of steps:
1. The digital library should include policies and rules specifying the management required.
2. The users of the digital library should be authenticated in some way
so they are known.
3. The content of the digital library should be shown to be authentic.
4. Payment should be made if access requires that in a particular case.
5. Users who are authorized to access a DO are allowed to do so.
6. Subsequent access with the DO may take place after retrieval to a user’s
site.
IBM has developed sophisticated technology
and digital library systems with support for rights management (Gladney 1998).
Xerox staff has developed a Digital Property Rights Language that relates
to step 1 above. Password schemes and systems like Kerberos relate to step
2. Hashing with MD5 or use of digital signatures can support step 3. E-commerce
mechanisms, especially those enabling micro-payments or subscriptions, relate
to step 4. Rules processing relates to step 5, as was done at Case Western
Reserve University – employing Prolog to work with users, user classes, documents,
and document classes – in order to find the lowest cost access solution. In
step 6, there usually is little control, unless a scheme like IBM’s Cryptolope
mechanism is involved wherein the DO is encapsulated with code that limits
access (e.g., prohibits printing).
Indexing, Resource Discovery, Searching, and Retrieving
Considering Figure 2 further, we clearly must support finding DOs, directly or through MDOs, so that they can be identified, retrieved, and used. Often, DOs and/or MDOs are automatically indexed so that some index structure is built to speed up search. Such indexing may build upon any manual indexing carried out by authors, other creators, or indexers. Automatic indexing also may involve first classifying DOs, such as when OCLC’s CORC project software suggests Dewey Decimal Classification entries for a WWW page that is being cataloged.
Indexes may be centralized or distributed. They may be two-level, allowing a resource discovery phase to proceed to find what source(s) should be included in the subsequent (lower) level search. Indexes also may have multiple parts, such as when a document has text, image, audio, or video content. Content-based indexing of multimedia information generally involves identifying and assessing features that characterize the DOs, whether they involve concepts, n-grams, words, keywords, descriptors, phonemes, textures, color histograms, eigenvalues, links, or user ratings.
Most commonly, searching in a digital library involves an information retrieval system or search engine. In some cases a database management system is used instead or underlies the retrieval system. In any case, retrieval will be more effective if a suitable scheme is used to combine the various types of evidence available (Belkin, Kantor, Fox, & Shaw 1995), to indicate if a DO may be relevant with respect to the query that is used to express the user’s information need.
Linking, Annotating, and Browsing
Once a DO is found, it often is appropriate to follow links from it to cited works (or vice versa). Further, notes can be recorded as annotations and linked back to the works, so they can be recalled later or shared with colleagues as part of collaborative activities. If suitable clustering is in place, other DOs that are “near” a given work may be examined. Or, using a classification system appropriate for the content domain, users may browse around in “concept space” and link at any point between concepts and related DOs. Browsing also can proceed based on any of the elements in the MDO. Thus, dates, locations, publishers, contributing artists, language, and other aspects may be considered to explore the collection or refine a search.
Interfaces and Interaction
Ultimately, users will connect through a human-computer interface and interact with the digital library, though in some cases the digital library may be an embedded system that is seen only indirectly (e.g., through a word processor that allows one to search for a quotation). Most commonly, a digital library has an interface for users to search, browse, follow links, retrieve, and read documents. As can be seen in Figure 4, that interface may be specialized according to what roles the user will play.
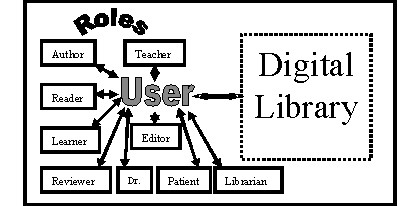
Figure 4. Users Direct
For example, the Computer Science Teaching
Center, a digital library of courseware about computing, requests that all
users, except those just browsing or searching, login to identify themselves.
Then it knows and tailors the interface so that suitably authorized users
can submit, review, or edit works. Further, CSTC encourages users to submit
courseware they have developed that others might download, and supports their
entering in suitable metadata as well as uploading their applets, demonstrations,
laboratory exercises, interactive multimedia training resources, etc. After
the work has been entered by the creator, it can be improved through peer
review and “certified” for public use, or even accepted for publication in
the ACM Journal of Educational Resources in Computing (JERIC) (Cassel
& Fox 2000). Thus, instead of requiring current complex and expensive
chains of processing for journal submissions, handling with digital libraries
may be implemented through this “users direct” model.
Following retrieval, users examine a list
of results or else work with more sophisticated schemes for visualizing and
managing results (Heath et al. 1995; Nowell & Hix 1992; Nowell & Hix
1993). Many other types of rich interaction are possible through innovative
digital library interfaces (Rao et al. 1995).
In particular, as can be seen in Figure 2, digital libraries may use special
software to present or render multimedia, hypertext, and hypermedia content.
Such software may be launched from a WWW browser, which typically only
supports a limited range of hypermedia. Real-time requirements must be satisfied
to ensure adequate quality of service when streaming content is involved,
especially if multiple streams are involved.
Also related to interaction with the digital library is the matter of workflow management. Especially with the “users direct” model, the various people interacting with a particular DO may leave some record of approval or review, which triggers others to continue with processing. For example, universities that are part of the Networked Digital Library of Theses and Dissertations (Fox 1997; Fox 2000; Fox 1999c) allow students to upload their works, make changes, secure approval by the graduate school, have cataloging information added by librarians, and ultimately release the suitably enhanced information for widespread access.
Finally, from Figure 2 we see that many digital libraries will have their own user interfaces. In addition, they may support gateway connections, using protocols like Dienst (Lagoze & Davis 1995) or Z39.50 (International Standard Maintenance Agency Z39.50, 2000). As we work toward world digital libraries, we must ensure that our interfaces support multimedia and multilingual access, as well as various schemes for interconnection with other digital libraries and resources.
Architectures and Interconnecting
Since the field of digital libraries is young, there still is active investigation regarding architecture, interconnection, and interoperability (Paepcke, Chang, Garcia-Molina & Winograd 1998). Figure 2 shows one, rather high-level, decomposition of a digital library into components. Given the range of legacy systems that are used today as parts of digital libraries, the actual situation often is more complex.
To simplify matters, several interconnection strategies have been explored. At Stanford, a bus approach has been used (Baldonado, Chang, Gravano, & Paepcke 1997; Melnik, Garcia-Molina, & Paepcke 2000; Paepcke 1999). Mediation code “wraps” around various collections or resources to make suitable conversions to representations supported by the bus and the other services connected to it.
Agents provide another interconnection mechanism (Birmingham 1995; Nicholas, Crowder, & Soboroff 2000; Sánchez, Flores, & Schnase 1999; Sánchez, Leggett, & Schnase 1997; Sánchez & Leggett 1997; Sánchez, Lopez, & Schnase 1998b). Many agent-based systems use KQML as the language for transporting knowledge constructs (Barceinas, Sánchez, & Schnase 1998). Yet another approach is the distributed scheme supporting federated search that underlies the Dienst system (Lagoze & Davis 1995; Lagoze & Payette 1998; Payette, Blanchi, Lagoze, & Overly 1999).
Nevertheless, currently it is not possible to identify the best architecture(s) for digital libraries. We must look to future technological developments and actual deployments as well as standardized performance testing to resolve such questions.